


// TODO Add references
// Suggestions welcome
Touching the Basics
In this series we will be going through a lot of things. But if you are at early stages of your career, I recommend you to get your hands dirty and concepts right, atleast to a reasonable proficiency, with the following fundamentals before you dive into other things. Hence this chapter is aptly called - the basics.
When beginning the journey you should get a decent foothold on
Software Engineering Overview
What is this all about? What is software? What is the expanse and depth of this domain from an eagle eye point of view?
Types of Careers and Roles
What are the different roles in software industry? For example, web developer, software engineer, dev-ops engineer, QA engineer, security engineer, observability engineer, site reliability engineer, technical architect, solution architect, technical writer, developer relations manager, developer advocate, technical lead, engineering manager, scrum master, chief of information, technology and security.
And which one may fit as your ikigai?
Proficiency in language and logic
Be comfortable writing code in any language of your choice. Python and JS are great starting points. Yet, the sky is the limit.
What you need to focus on is what are the typical repeating concepts every language is trying to address in its own unique way. After that, every new language is just about getting some syntax and libraries memorised. And now search engines, IDEs, online content and AI make this job even easier for us.
For ex. if/else, looping, try/catch, async operations, threads, functional programming, design patterns etc. These are some of the repeating patterns.
Time for a story
Talking of programming languages, their generations and evolution of my own journey in using and developing them.
In our days at IIT Kanpur we began with Java. And by the third year we kids had built projects like a C++ compiler (in C++!) :D We had played with plethora of languages like C#, C++, R, Php, Python, Perl, Objective C, SQL, Javascript and whatever else we needed to pick, play and adopt when building our projects. During my early professional career with Oracle, iXigo and my first startup product called Metataste - a taste based movie recommendation engine between 2011-14, I work in mostly Objective C, Java, R and a little bit of Haskell to understand functional programming. In my entire experience, after seeing the first 3 languages of different kinds, I knew I can work in any new language.
In 2014-15, I decided to put an end to Metataste (a yet to be matched product deserving to be alive till date - another story). It was a vector and content based personalisation engine using Mongodb and Lucene in dual consistency mode. In order to build this in a configure over code manner, so that it was always flexible and adaptable, we developed a Java framework over Tomcat.
By that time I had worked mostly in Java based projects for around 8 years. I found it a bit too verbose and definitely not a silver bullet for everything! So came Nodejs in 2014, on top of which was laid the first stone (line of code) of Elasticgraph starting 2015. Given my proclivity to abstract repeated patterns of code, in between 2017 to 20 I developed an English likes scripting language using Elasticgraph in Nodejs, using the lovely Pegjs parser. You can watch me talking about the Elasticgraph project at Elastic meetup Bangalore in 2023, where Shay Bannon the founder of Elastisearch was also present. in my video I start by sharing the real life story of an email exchange between me and Shay back in 2018 :-)
A sneak peak into Easy Scriptling Language as I call it
The code I am about to show below does the following things -
It scrolls over an ES index, fetches some more documents, at the same time creates documents when lookups fail, joins data across relationships, avoids N+1 query problem (via in mem caching), transforms the data, stores computed documents in other ES indices using bulk requests, manages 'foreign key' connections, data dependencies and also materialized views! This is perhaps 70 lines of code along with some configuration files where the relationship, default joins and materialized views models are defined. All of what I just mentioned is happening here. A lot of stuff!
If same logic is to be implemented using pure third generation language code using Elasticsearch Nodejs client library, this same logic would be be of a few thousand lines of very complex code. It will also take a reasonably smart engineer to write it well. In Java, it may well become even double the lines of TS code (TS is quite shorthand compared to Java)
const fillSpeakersTranslatorsAndLinkWithEvent = [
'iterate over old-contents where {$exist: event_id} as old-content. Get 25 at a time. Flush every 5 cycles. Wait for 100 millis',
[
'get event *old-content.event_id',
'if *event is empty, display "empty event", *old-content.event_id',
'if *event is empty, stop here',
'search old-content-to-audio-channel where {content_id: *old-content._id} as cac',
'async each *cac.hits.hits as old-content-to-audio-channel'
[
'get old-audio-channel *old-content-to-audio-channel.audiochannel_id as old-audio-channel', //No need to mention _source or fields. Both places, including top level object will be checked for existence of audiochannelId field
'search first person where {_id: *old-audio-channel.speaker_id} as person.', //Creates person in index if not found there. Also sets person entity viz id+type as key in ctx.data, query as key with value being result in ctx.data
//Handle event.speakers/translators. This guy is either a speaker or a translator. Set the relevent linking
//Initializer
'roleType is speaker if *old-audio-channel.translation_type is empty. Else is translator',
'roleFeatures are {person._id: *old-audio-channel.speaker_id, primaryLanguages._id: *old-audio-channel.language_id}',
//Can include pure JS functions within the script also
(ctx) => {
//TODO fix this 'roleFeatures.translationType is *old-audio-channel.translation_type if *roleType is translator.',
if (ctx.get('roleType') === 'translator') {
const translationType = ctx.get('old-audio-channel')._source.translation_type
ctx.get('roleFeatures').translationType = translationType
}
return ctx
},
'search first *roleType where *roleFeatures as speakerOrTranslator. Create if not exists.',
'if *speakerOrTranslator is empty, display "empty speaker", *roleFeatures, *roleType',
'if *speakerOrTranslator is empty, stop here',
(ctx) => {
const speaker = ctx.get('speakerOrTranslator')
const speakerBody = speaker._source || speaker.fields
const pmName = _.get(_.first(speakerBody.primaryLanguages), 'fields.english.name')
if (_.isObject(pmName)) {
debug('throw stopHere error to break the loop', JSON.stringify(speaker))
throw new Error('stopHere')
}
},
//'display *roleType, *speakerOrTranslator._id, *roleFeatures',
'link *speakerOrTranslator with *event as events',
],
],
(ctx) => debug('Done ' + n++ + ' iterations')
];
//Now run the script
eg.dsl.execute(fillSpeakersTranslatorsAndLinkWithEvent);
Elasticgraph was written using Vim in Nodejs using Javascript in the days when async/await was not a standard JS feature. We used Q and async-q the promise libraries prominently in use at that point. We also made an UI admin panel which was auto-generated using configurations again! Zero coding was required for a user to set up an entity model domain CRUD API (both REST + Socket) using Nodejs and a ReactJS UI. You can find a video demonstration of the Elasticgraph featureset here.
From Elasticgraph which is great for Elasticsearch + Nodejs based usecase, the buck of innovation and scope of work moved forward to solving the larger problem for modern microservices and serverless based use cases, which can be reasonably complex in nature. We adopted 'types' in the JS world using Typescript, in 2022 when we started building V1 of Godspeed Meta-Framework - which provides fourth generation abstractions in development of modern API and event driven systems over 3rd gen frameworks like currently supported Nodejs. We have a Java version under works. I eventually would love to see the meta-framework with its standardised abstractions cover more and more prominent languages as a standard.
Now if you give me any other language to pick on, I should be able to deliver you my first well done project in couple of weeks. Why? Because I have by now seen most concepts in programming langauges. The patterns just keep repeating with minor to major tweaks. But the fundamentals of logic and datastructures and algorithm and computation remain the same, and will always remain so, no matter how many generations of languages come and go. So if you have visualised and understood these concepts now, you can switch easily between tools.
Business Logic and Boilerplate
The logic which serves a customer's or user's need is business logic. The logic and integration code that enables business logic to run without hiccups is boilerplate. Boilerplate does not directly serves the user, the business or the world. It serves the basic functioning of the software. For ex. multiplexing your queries into a bulk request, then de-multiplexing the responses for further handling of respective API calls.
The basic functioning of the software enables the development of business features on top of it. The features in turn are what serve the user and the cause. Not the boilerplate (at least not directly).
I my tryst with programming and professional software development, between our first semester course "Programming in Java" in 2002 to '23 so far, I have seen that in the oceans of lines of code lie hidden the real pearls - the actual business logic. And hidden like a needle in a haystack - the bug!
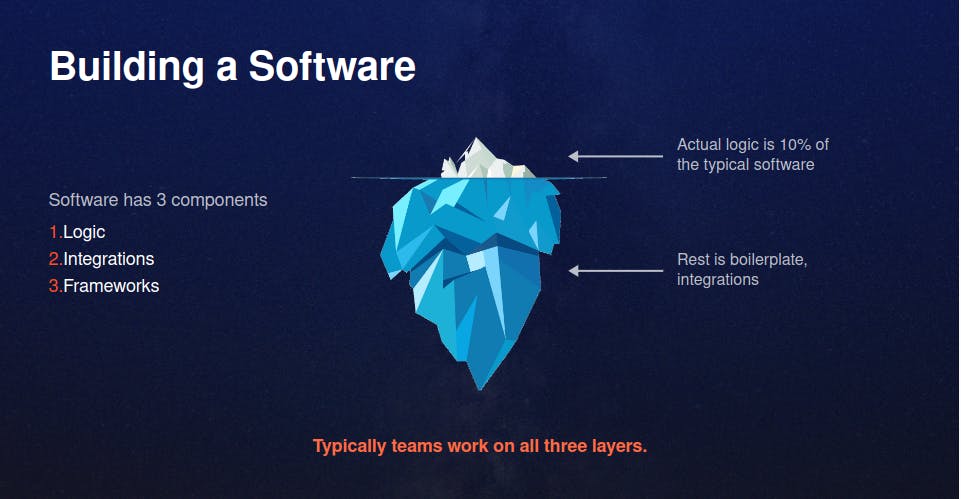
From most to almost all engineering teams till date spend majority amount of their time and effort in writing, managing and debugging code which is not serving the user, but enabling them to serve the user. For ex. Initialising an http server, or setting up and querying a database or API with authentication and token refresh.
I remember a Drone Pilot Marketplate project I did as part of a team of 3 backend engineers, and a larger team with frontend engineers, testing engineers , scrum master and product analyst. All the backend team did for three months was write APIs with validations, try/catch/retry and finally the pearl in between all of this - the actual funtionality of the app. The logic layer was so thin! Absolutely non-existent! We were simply exposing the CRUD over a database via REST APIs and doing validations of incoming API call inputs by hand using AJV. And as is the case with typical such implementations - there was not just extra effort, but questionable outcome. There were three sources of truth floating around between the team - the db schema, the coded API validations and the Postman collection going around in emails.
With something like Godspeed's meta-framework this job could have been finished many times faster and better, with single source of truth, using Schema Driven Development guardrail. It would have saved time not just of the backend team, but also the frontend, the QA, the scrum master, and most importantly - the customer.
Unless you are a student learning the very basics, or somebody who is doing this job for survival and you sell time for money (in which case I sincerely request you to reconsider your assumptions), you would like to make better use of your creative skills & your precious time to keep on innovating and growing more and more with higher challenges. Or do meditation, cooking or spend time with family in the freed up hours! I remember our scrum master would often call us desperately even during nighttime, saying hey guys - this week is the release. Can we push harder? And what did we push harder? Writing CRUD APIs with three sources of truth! Not his decision, not his fault, but loss of all.
Imagine if this product could have been launched in half the time and with lesser chaos? How much benefit would it have served the customer? And the team?
Data & datastructures
There are four types of data: image, audio, video and text.
Programming is but reading, transforming, computing and sending data.
Data is organised and represented in structures (data-structures).
Multiple structures can come together to form more complex structures which people call types. Or a Class in Java, a struct in C, a 'document' in a Nosql database. For ex. Stone, tree, animal, human.
Data and structures are everywhere - in a file, a database or memory of a software.
Whether its the file system, datastore, API, system or process memory - everything is a source or store of data, a place where you send or retrieve data from. Its called datasource!
In initial stages of learning an ample effort and attention needs to be invested in understanding and playing with data, structures and then as well types. It opens the mind. It starts with the very basic ones - an boolean, string, number, array, hash etc. Playing with map, reduce, filter helps in learning and as well improving the skill of visualisation.
A good programmer can visualise data in its different forms (structures) and connections (relationships). They start by visualising well the input picture, the output picture, and they visualise the path to realise the outcome. They document it. Whether as
// TODO comment in codeor in A Jira or Github spec. Then finally, they proceed for implementation.
Algorithms
Next up for algorithms - we sometimes need to do more complex work than just transforming data from one format to another like map-reduce in memory. This is the beginning.
An inspired programmer travels far and wide with the travelling salesman problem, Kruskal's shortest path algorithm, binary search, heap sort and the like. They admire the sheer human ability to visualise and solve puzzles. And so can you! Working on puzzles, datastructures, algorithms, trying to solve a problem with least computational complexity (Big O notation) - you should not prepare these because you have to prepare for an interview. These have to be part of your initial journey to open your mind! To exercise those muscles which will make you a 10X engineer.
Basic Unix Commands
IMO the best softwares of the world are written in unix based systems. One should know fundamentals of operating systems and basic unix commands and tools, because they allow you to be more efficient and empowered in your development cycle. Period. A very basic knowledge of shell programming, and few commands goes a long way in helping us in day to day work, much more efficiently.
My personal useful list of commands to play with: cd, ls, cp, mv, ls, ln, tar, curl, ps, netstat, kill, pkill, xargs, grep, sed, find, awk, top, htop, sudo, cat, more, less.
They can be combined and used together in tandem. My favourite one to find services by process name match and stop all of them together.
"ps -ef | grep service_name | awk '{print $2}' | xargs kill -9"
About Errors, Debugging and Importance of Testing
An error or bug is unexpected behaviour of the software.
// TODO add a blog on how to debug an error or bug!
When a bug bites on local machine it hurts less, than when in production. Quality of user experience makes or breaks the game of any software adoption and growth. We humans have a negativity bias. One bad UX is most of the times worse than 99 good UX. In order to ensure we have a sound quality, testing is of paramount importance. Else, the same old story goes - it worked on my laptop! :D
So teams follow a proper process called SDLC in which there is another sub-process called CI/CD automation. Teams write different kind of unit, integration and functional tests which are run as part of CI/CD automation, along with scans like static code scan, vulnerability scan, network scan etc. Developers like me often do not write test cases. But they need to be written and automated by someone. And ideally by the one who wrote the code in the first place!
// TODO add a best practices blog
Conclusion
There is so much to talk about when we start of in this journey of programming and software development. Will keep on updating these entries as I maintain this series with the help of friends and community like you. I will stay open for community to also share suggestions or write a guest post and help improve this content for benefit of all.
Feel free to reach me out with your thoughts. Stay tuned for the next blogs in the series on advanced programming topics.